大数据分析复习与考试总结
刘盛华部分
第二章 大数据分析技术与系统
第1节 数据与计算的演变
第2节 大数据分布式计算模型
大数据分析算法特点:
以优化为中心,多轮迭代直到收敛,容错高。
- 序列计算 在处理器上按照先后顺序进行 将问题分解为指令序列,按顺序依次执行指令,在一个处理器上执行所有指令,任意时间片里处理器只有一条指令在执行。
- 并行计算 将问题分解为可以并发处理的子问题 每一个子问题分为逻辑虚列 需要一个总体的控制机制
在大数据处理中 O(n2)算法很难处理intractable
- 算法可扩展(scalable)性

- 当c=0,A是线性scalable,当 是super scalable
Cost Measures
- Communication cost = total I/O of all processes
- Elapsed communication cost = max of I/O along
any path
第3节 分布式计算系统:map-reduce
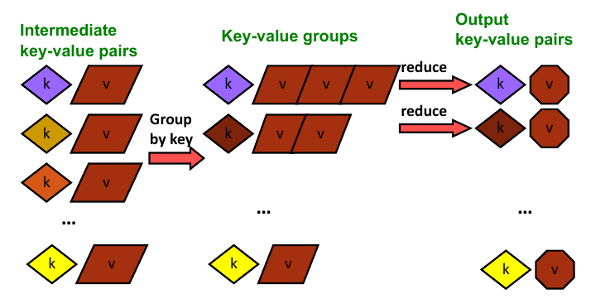
**Map:**读取输入值,生成key-value对。 用户设计map function 提取感兴趣的信息
Group by keys: sort and shuffle 系统检索所有键key值,输出key-value
Reduce: 设计reduce function: aggregate summarize filter transform
第4节 分布式计算应用
参数更新方案
- 同步更新Bulk synchronous parallel(BSP)
每一轮迭代设置同步点,统一更新参数,进入下一轮迭代。最大程度上模拟了序列计算,结果基本一致,具有同样的理论保障。缺点 同步点的设置导致BSP低效,网络速度慢时延大,计算机速度不一致导致等待。
- 异步更新Async
完全没有参数同步,本地数据不全面,单个节点只有部分数据,独立更新参数,从整体上看结果不正确。不同机器上更新次数差异很大,参数相互依赖,参数过期。
- 半同步更新:综合上面两个。
解决局部服务器损坏问题
问题:copy数据over network需要时间
解决:将电脑安置在靠近数据的地方 或 储存多份文件的拷贝
Storage infrastructure,file system
Google GFS。Hadoop:HDFS
Programming model
分布式文件系统
Chunk server 将文件分割成连续的chunks,一般每个chunk 16-64MB,每份chunk都复制两三份,让复制文件保存在不同的轨道上。
Master Node aka Name Node 储存metadata(元数据)的节点,可以被复制
Client Library for file access 让master 寻找对应chunk server,直接和chunk server连接获取数据。
第三章 大数据统计分析
第1节 相关性分析
传统统计相关性
- 肯德尔相关系数
- 皮尔森相关系数
- 斯皮尔曼相关系数(序形式)
大数据统计相关性
- 互信息
第2节 大数据统计:相似查找LSH
- Shingling
- Min-Hashing
- LSH 局部敏感Hashing
第3节 大数据计数:CMS
- Min-sketch 大数据统计与计数
第四章 大数据机器学习
第2节 数据降维
SVD
第3节 基于决策树的方法
- 信息熵/信息增益计算
- Random Forest
- GBDT
第4节 深度神经网络
- BERT
- Transformer
第八章 大图挖掘与分析
大图的模式分析-degree的幂律分布
最密子图检测
Graph with temporal information
D-cube
HoloScope
EigenPulse
第九章 社会媒体分析
第2节 PageRank形式化与流
第3节 PageRank收敛性
第4节 大规模数据的PageRank计算
靳小龙部分
第五章 数据驱动的自然语言处理
第2节 词法分析-中文分词
- 基于长短时记忆网络 LSTM 的中文分词
第4节 内容分析-文本分类
- 文本分类
- TextCNN模型
第六章 文本大数据分析
第2节 文本表达
单词表示方法
句子表示方法
第3节 文本匹配
基于规则的文本匹配
基于学习的文本匹配
第4节 文本生成
文本生成任务
方法与评价方式
第七章 知识计算
第1节 知识图谱简介
第2节 实体抽取
第3节 关系抽取
第4节 知识推理与计算
利用已有的知识推理隐含或潜在的知识。



